30. 網格 (Rasters)¶
PostGIS 支援另一種稱為網格的空間資料類型。網格資料與幾何資料非常相似,都使用笛卡爾坐標和空間參考系統。然而,網格資料不是以向量資料呈現,而是以由像素和頻帶組成的 n 維矩陣表示。頻帶定義了您擁有的矩陣數量。每個像素都儲存一個對應於每個頻帶的值。因此,像 RGB 影像這樣的 3 頻帶網格,每個像素都會有 3 個對應於紅色、綠色和藍色頻帶的值。
雖然您在電視螢幕上看到的漂亮圖片是網格,但網格可能看起來沒有那麼令人興奮。簡而言之,網格是固定在坐標系統上的矩陣,其值可以代表您希望它們代表的任何事物。
由於網格存在於笛卡爾空間中,因此網格可以與幾何圖形互動。PostGIS 提供了許多以網格和幾何圖形作為輸入的函式。許多應用於網格的操作將會產生幾何圖形。常見的有 ST_Polygon、ST_Envelope、ST_ConvexHull 和 ST_MinConvexHull,如下所示。當您將網格轉換為幾何圖形時,輸出的會是網格的 ST_ConvexHull。
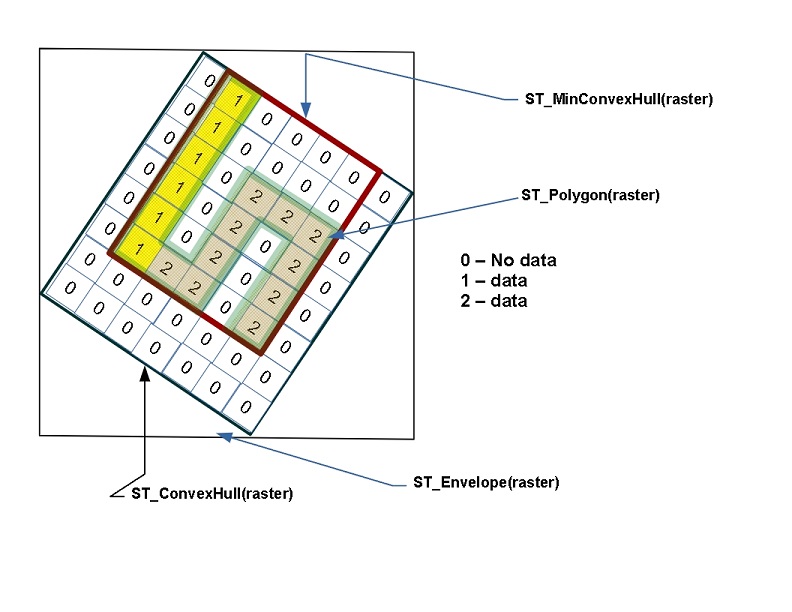
網格格式通常用於儲存高程資料、溫度資料、衛星資料和主題資料,這些資料代表諸如環境污染、人口密度和環境危害事件等事物。您可以使用網格來儲存任何具有有意義坐標位置的數值資料。唯一的限制是,在特定頻帶中的所有資料,數值資料類型必須相同。
雖然網格資料可以在 PostGIS 中從頭開始建立,但更常見的方法是使用 PostGIS 隨附的 raster2pgsql 命令列工具,從各種格式載入網格資料。在執行這一切之前,您必須先執行以下命令,在您的資料庫中啟用網格支援
CREATE EXTENSION postgis_raster;
30.1. 從幾何圖形建立網格¶
我們先從從向量資料建立網格資料開始,然後再轉向從網格來源載入資料的更令人興奮的方法。您會發現網格資料隨處可得,而且通常可以從各種政府網站免費取得。
我們將從使用 ST_AsRaster 函式將一些幾何圖形轉換為網格開始,如下所示。
CREATE TABLE rasters (name varchar, rast raster);
INSERT INTO rasters(name, rast)
SELECT f.word, ST_AsRaster(geom, width=>150, height=>150)
FROM (VALUES ('Hello'), ('Raster') ) AS f(word)
, ST_Letters(word) AS geom;
CREATE INDEX ix_rasters_rast
ON rasters USING gist(ST_ConvexHull(rast));
上面的範例使用 PostGIS 3.2+ ST_Letters 函式,從由字母形成的幾何圖形建立一個表格 (rasters)。與幾何圖形類似的網格可以利用空間索引。用於網格的空間索引是一種函數索引,可以索引網格的幾何圖形凸包。
您可以使用以下查詢查看網格的一些實用中繼資料,該查詢利用 postgis 網格 ST_Count 函式來計算具有資料的像素數量,以及 ST_MetaData 函式來為我們的網格提供各種實用的背景資訊。
SELECT name, ST_Count(rast) As num_pixels, md.*
FROM rasters, ST_MetaData(rast) AS md;
name | num_pixels | upperleftx | upperlefty | width | height | scalex | scaley | skewx | skewy | srid | numbands
--------+------------+------------+-------------------+-------+--------+--------------------+---------------------+-------+-------+------+----------
Hello | 13926 | 0 | 77.10000000000001 | 150 | 150 | 1.226888888888889 | -0.5173333333333334 | 0 | 0 | 0 | 1
Raster | 11967 | 0 | 75.4 | 150 | 150 | 1.7226319023207244 | -0.5086666666666667 | 0 | 0 | 0 | 1
(2 rows)
注意
網格函式有兩個層級。有些函式(例如 ST_MetaData)在網格層級運作,還有一些函式(例如 ST_Count 函式和 ST_BandMetaData 函式)在頻帶層級運作。postgis 網格中大多數在頻帶層級運作的函式,一次只處理一個頻帶,並假設您要處理的頻帶是 1。
如果您有多頻帶網格,並且需要計算頻帶 1 以外的頻帶中非無資料值的像素,則您需要明確指定頻帶號碼,如下所示:ST_Count(rast,2)。
請注意,所有網格都有 150x150 的維度。這不是理想的。這表示為了強制執行這一點,我們的網格會被擠壓成各種形狀。如果我們能夠看到眼前網格的醜陋之處就好了。
30.2. 使用 raster2pgsql 載入網格¶
raster2pgsql 是一個通常與 PostGIS 捆綁在一起的命令列工具。如果您使用的是 Windows,並使用了應用程式堆疊組建器 PostGIS 套件,您會在資料夾 C:\Program Files\PostgreSQL\15\bin 中找到 raster2pgsql.exe,其中 15 應替換為您正在執行的 PostgreSQL 版本。
如果您使用的是 Postgres.App,您會在其他 Postgres.app CLI 工具中找到 raster2pgsql。
在 Ubuntu 和 Debian 上,您需要
apt install postgis
安裝 PostGIS 命令列工具。這也可能會安裝額外的 PostgreSQL 版本。您可以使用 pg_lsclusters 命令查看 Debian/Ubuntu 中的叢集清單,並使用 pg_dropcluster 命令刪除它們。
對於此練習和後續練習,我們將使用 nyc_dem.tif,它位於檔案 PG Raster Workshop Dataset https://postgis.dev.org.tw/stuff/workshop-data/postgis_raster_workshop.zip 中。對於某些幾何/網格範例,我們也將使用從先前章節載入的 NYC 資料。如果您沒有載入 tif 檔案,您可以使用 pg_restore 命令列工具或 pgAdmin 的「還原」選單,在您的資料庫中還原 zip 檔案中包含的 nyc_dem.backup。
注意
此網格資料來自 NYC DEM 1-foot Integer,這是一個 3GB 的 DEM tif 檔案,表示相對於海平面的高程,其中已移除建築物和水上區域。然後我們建立了一個較低解析度的版本。
raster2pgsql 工具與 shp2gpsql 類似,只是它不是將 ESRI 形狀檔案載入 PostGIS 幾何/地理表格中,而是將任何 GDAL 支援的網格格式載入網格表格中。就像 shp2pgsql 一樣,您可以將來源的空間參考 ID (SRID) 傳遞給它。與 shp2pgsql 不同,如果您的來源資料具有合適的中繼資料,它可以推斷來源資料的空間參考系統。
如需完整了解所提供的所有可能切換選項,請參閱 raster2pgsql 選項。
raster2pgsql 提供的一些其他值得注意的選項(我們將不會介紹)是
能夠標示來源的 SRID。相反,我們將依賴 raster2pgsql 的猜測能力。
能夠設定 nodata 值,如果未指定,raster2pgsql 會嘗試從檔案中推斷。
能夠載入資料庫外的網格。
要載入我們資料夾中的所有 tif 檔案並建立概觀,我們會執行以下操作。
raster2pgsql -d -e -l 2,3 -I -C -M -F -Y -t 256x256 *.tif nyc_dem | psql -d nyc
-d 如果表格已存在,則刪除表格
上面的命令使用 -e 來立即載入,而不是在交易中提交
-C 設定網格約束,這對於 raster_columns 顯示資訊很有用。您可能想要結合 -x 來排除範圍約束,這是一種檢查速度緩慢的約束,也會妨礙表格中未來的載入。
-M 在載入後執行 vacuum 和 analyze,以改善查詢規劃器統計資訊
-Y 以 50 個批次使用複製。如果您執行的是 PostGIS 3.3 或更高版本,您可以使用 -Y 1000 來以 1000 個批次進行複製,甚至可以使用更高的數字。這會執行得更快,但會使用更多的記憶體。
-l 2,3 建立概觀表格:o_2_ncy_dem 和 o_3_nyc_dem。這對於檢視資料很有用。
-I 建立空間索引
-F 新增檔案名稱,如果您只有一個 tif 檔案,這有點毫無意義。如果您有多個檔案,這對於告訴您每個列來自哪個檔案會很有用。
-t 設定區塊大小。請注意,如果您不確定要使用的最佳大小,請改用 -t auto,raster2pgql 會使用與 tif 檔案中相同的平鋪。輸出會告訴您它選擇的區塊大小。如果它看起來很大或很奇怪,請取消。原始檔案的大小為 300x7,這不是很理想。
使用 psql 來針對資料庫執行產生的 sql。如果您想要改為傾印到檔案,請使用 > nyc_dem.sql
在此範例中,我們只有一個 tif 檔案,因此我們可以指定完整檔案名稱,而不是 *.tif。如果檔案不在您目前的目錄中,您也可以使用 *.tif 指定資料夾路徑。
注意
如果您使用的是 Windows,並且需要參考資料夾,請務必包含磁碟機代號,例如 C:/workshop/*.tif
您經常會在 PostGIS 行話中聽到術語網格圖磚和網格互換使用。網格圖磚實際上對應於網格欄中的特定網格,它是較大網格的子集,例如我們剛才載入的 NYC dem 資料。這是因為當網格從大型網格檔案載入到 PostGIS 中時,它們會被切成許多列以使其易於管理。然後,每個列中的每個網格都是較大網格的一部分。每個圖磚涵蓋由您指定的區塊大小標示的相同大小的區域。網格很遺憾地受到 1GB PostgreSQL TOAST 限制和還原過程緩慢的限制,因此我們需要切分它們,才能獲得良好的效能,甚至才能儲存它們。
30.3. 在瀏覽器中檢視網格¶
雖然 pgAdmin 和 psql 目前還沒有機制可以檢視 PostGIS 柵格資料,但我們有幾個選項。對於較小的柵格資料,最簡單的方法是使用內建的 PostGIS 柵格函數,例如 ST_AsPNG 或 ST_AsGDALRaster(列於PostGIS 柵格輸出函數)輸出為網頁友善的柵格格式,如 PNG。當你的柵格資料變得更大時,你會希望使用 QGIS 之類的工具來完整檢視它們,或使用 GDAL 系列的命令行工具,如 gdal_translate 將它們匯出為其他柵格格式。請記住,PostGIS 柵格資料是為分析而設計的,而不是為了產生漂亮的圖片讓你觀看。
一個需要注意的地方是,預設情況下,所有不同的柵格類型輸出都是停用的。為了使用這些功能,你需要啟用驅動程式,全部或部分啟用,詳情請參閱啟用 GDAL 柵格驅動程式。
SET postgis.gdal_enabled_drivers = 'ENABLE_ALL';
如果你不想每次連線都執行此操作,你可以使用以下方式在資料庫層級設定:
ALTER DATABASE nyc SET postgis.gdal_enabled_drivers = 'ENABLE_ALL';
每次新的資料庫連線都會使用該設定。
執行以下查詢,並將輸出複製並貼到網頁瀏覽器的網址列中。
SELECT 'data:image/png;base64,' ||
encode(ST_AsPNG(rast),'base64')
FROM rasters
WHERE name = 'Hello';

對於目前建立的柵格資料,我們沒有指定波段數量,也沒有定義它們與地球的關係。因此,我們的柵格資料具有未知的空間參考系統 (0)。
你可以將柵格資料的外骨骼視為幾何。一個被幾何外殼包裹的矩陣。為了進行有用的分析,我們需要對柵格資料進行地理參考,這表示我們希望每個像素(矩形)代表某些有意義的空間區域。
ST_AsRaster 有許多重載的表示形式。先前的範例使用了最簡單的實現方式,並接受了預設參數,即 8BUI 和 1 個波段,沒有資料為 0。如果你需要使用其他變體,你應該使用具名的參數呼叫語法,這樣你就不會意外地使用到錯誤的函數變體或收到 function is not unique 錯誤。
如果你從具有空間參考系統的幾何開始,你最終會得到一個具有相同空間參考系統的柵格資料。在下一個範例中,我們將在紐約用鮮豔的顏色標示我們的文字。我們還將使用像素比例而不是寬度和高度,以便我們的柵格像素大小代表 1 公尺 x 1 公尺的空間。
INSERT INTO rasters(name, rast)
SELECT f.word || ' in New York' ,
ST_AsRaster(geom,
scalex => 1.0, scaley => -1.0,
pixeltype => ARRAY['8BUI', '8BUI', '8BUI'],
value => CASE WHEN word = 'Hello' THEN
ARRAY[10,10,100] ELSE ARRAY[10,100,10] END,
nodataval => ARRAY[0,0,0], gridx => NULL, gridy => NULL
) AS rast
FROM (
VALUES ('Hello'), ('Raster') ) AS f(word)
, ST_SetSRID(
ST_Translate(ST_Letters(word),586467,4504725), 26918
) AS geom;
如果我們檢視這個結果,我們會看到一個沒有被壓縮的彩色幾何。
SELECT 'data:image/png;base64,' ||
encode(ST_AsPNG(rast),'base64')
FROM rasters
WHERE name = 'Hello in New York';

為柵格資料重複上述步驟。
SELECT 'data:image/png;base64,' ||
encode(ST_AsPNG(rast),'base64')
FROM rasters
WHERE name = 'Raster in New York';

更重要的是,如果我們重新執行
SELECT name, ST_Count(rast) As num_pixels, md.*
FROM rasters, ST_MetaData(rast) AS md;
請觀察紐約條目的元數據。它們具有紐約州平面公尺空間參考系統。它們也具有相同的比例。由於每個單位都是 1x1 公尺,因此 Raster 這個詞的寬度現在比 Hello 更寬。
name | num_pixels | upperleftx | upperlefty | width | height | scalex | scaley | skewx | skewy | srid | numbands
-------------------+------------+------------+-------------------+-------+--------+--------------------+---------------------+-------+-------+-------+----------
Hello | 13926 | 0 | 77.10000000000001 | 150 | 150 | 1.226888888888889 | -0.5173333333333334 | 0 | 0 | 0 | 1
Raster | 11967 | 0 | 75.4 | 150 | 150 | 1.7226319023207244 | -0.5086666666666667 | 0 | 0 | 0 | 1
Hello in New York | 8786 | 586467 | 4504802.1 | 184 | 78 | 1 | -1 | 0 | 0 | 26918 | 3
Raster in New York | 10544 | 586467 | 4504800.4 | 258 | 76 | 1 | -1 | 0 | 0 | 26918 | 3
(4 rows)
30.4. 柵格空間目錄表¶
與幾何和地理類型類似,柵格有一組目錄,顯示資料庫中所有的柵格欄位。這些是 raster_columns 和 raster_overviews。
30.4.1. raster_columns¶
raster_columns 檢視與 geometry_columns 和 geography_columns 類似,為柵格欄位提供了非常相似的數據和更多資訊。
SELECT *
FROM raster_columns;
瀏覽此表,你會發現
r_table_catalog | r_table_schema | r_table_name | r_raster_column | srid | scale_x | scale_y | blocksize_x | blocksize_y | same_alignment | regular_blocking | num_bands | pixel_types | nodata_values | out_db | extent | spatial_index
----------------+----------------+--------------+-----------------+------+---------+---------+-------------+-------------+----------------+------------------+-----------+-------------+---------------+--------+--------+---------------
nyc | public | rasters | rast | 0 | | | | | f | f | | | | | | t
nyc | public | nyc_dem | rast | 2263 | 10 | -10 | 256 | 256 | t | f | 1 | {16BUI} | {NULL} | {f} | | t
nyc | public | o_2_nyc_dem | rast | 2263 | 20 | -20 | 256 | 256 | t | f | 1 | {16BUI} | {NULL} | {f} | | t
nyc | public | o_3_nyc_dem | rast | 2263 | 30 | -30 | 256 | 256 | t | f | 1 | {16BUI} | {NULL} | {f} | | t
(4 rows)
rasters 表格中令人失望的一行,其中大部分資訊未填寫。
與幾何和地理不同,柵格不支援類型修飾符,因為類型修飾符空間太有限,而且有比類型修飾符中能容納的更多關鍵屬性。
柵格改為依賴約束,並將這些約束讀回為檢視的一部分。
查看我們使用 raster2pgsql 載入的表格中的其他列。由於我們使用了 -C 參數,raster2pgsql 為 srid 和其他它可以從 tif 讀取或我們傳入的資訊添加了約束。使用 -l 參數產生的概觀表格 o_2_nyc_dem 和 o_3_nyc_dem 也會顯示出來。
讓我們嘗試在我們的表格中添加一些約束。
SELECT AddRasterConstraints('public'::name, 'rasters'::name, 'rast'::name);
你會被一堆關於你的柵格資料一團糟且無法約束的通知轟炸。如果你再次查看 raster_columns,rasters 的情況仍然是許多空白行的令人失望的結果。
為了應用約束,表格中的所有柵格資料都必須可被至少一條規則約束。
或許我們可以這樣做,我們就謊稱我們所有的資料都在紐約州平面系統中。
UPDATE rasters SET rast = ST_SetSRID(rast,26918)
WHERE ST_SRID(rast) <> 26918;
SELECT AddRasterConstraints('public'::name, 'rasters'::name, 'rast'::name);
SELECT r_table_name AS t, r_raster_column AS c, srid,
blocksize_x AS bx, blocksize_y AS by, scale_x AS sx, scale_y AS sy,
ST_AsText(extent) AS e
FROM raster_columns
WHERE r_table_name = 'rasters';
啊,有進展了
t | c | srid | bx | by | sx | sy | e
----------+------+-------+-----+-----+----+----+------------------------------------------
rasters | rast | 26918 | 150 | 150 | | | POLYGON((0 -0.90000000000..
(1 row)
你可以約束你所有的柵格資料越多,你會看到更多欄位被填寫,並且你也可以在柵格資料中的所有圖塊上執行更多操作。請記住,在某些情況下,你可能不想套用所有約束。
例如,如果你計劃將更多資料載入你的柵格表格,你會想要跳過範圍約束,因為這會要求所有柵格資料都在範圍約束的範圍內。
30.4.2. raster_overviews¶
柵格概觀欄位同時出現在 raster_columns 元目錄和另一個名為 raster_overviews 的元目錄中。概觀主要用於加快在高縮放層級的檢視速度。它們也可以用於快速的概略分析,提供不太精確的統計資料,但速度比應用於原始柵格表格快得多。
要檢視概觀,請執行
SELECT *
FROM raster_overviews;
你會看到以下輸出
o_table_catalog | o_table_schema | o_table_name | o_raster_column | r_table_catalog | r_table_schema | r_table_name | r_raster_column | overview_factor
----------------+----------------+--------------+-----------------+-----------------+----------------+--------------+-----------------+-----------------
nyc | public | o_2_nyc_dem | rast | nyc | public | nyc_dem | rast | 2
nyc | public | o_3_nyc_dem | rast | nyc | public | nyc_dem | rast | 3
(2 rows)
raster_overviews 表格僅提供概觀因子和父表格的名稱。所有這些資訊都可以透過 raster2pgsql 的概觀命名慣例自己推斷出來。
overview_factor 會告訴你該列相對於其父列的解析度。overview_factor 為 2 表示 2x2 = 4 個圖塊可以放入一個 overview_2 圖塊中。同樣地,overview_factor 為 3 表示原始的 2x2x2 = 8 個圖塊可以塞入一個 overview_3 圖塊中。
30.5. 常見的柵格函數¶
postgis_raster 擴展有超過 100 個函數可供選擇。PostGIS 柵格功能是仿照 PostGIS 幾何支援設計的。你會發現柵格和幾何之間有功能重疊,在合理的情況下。你將使用到的常見功能,在幾何世界中有等效的功能,包括 ST_Intersects、ST_SetSRID、ST_SRID、ST_Union、ST_Intersection 和 ST_Transform。
除了那些重疊的函數之外,它還支援柵格之間以及柵格和幾何之間的 && 重疊運算符。它還提供了許多與幾何一起使用或非常特定於柵格的函數。
你需要像 ST_Union 這樣的函數來重建一個區域。由於效能會隨著函數需要分析的像素越多而變慢,因此你需要一個快速運作的函數 ST_Clip 來將柵格裁剪到僅限於你分析的感興趣部分。
最後,你需要 ST_Intersects 或 && 來放大包含你的感興趣區域的柵格圖塊。&& 運算符比 ST_Intersects 快。兩者都可以利用柵格空間索引。我們將首先介紹這些基礎函數,然後再繼續介紹其他章節,我們將在這些章節中將它們與其他柵格和幾何函數一起使用。
30.5.1. 使用 ST_Union 合併柵格¶
柵格的 ST_Union 函數,與幾何等效的 ST_Union 相同,將一組柵格聚合為一個柵格。然而,與幾何一樣,並非所有柵格都可以合併在一起,但柵格合併的規則比幾何規則更複雜。在幾何的情況下,你只需要有相同的空間參考系統,但對於柵格來說,這是不夠的。
如果你嘗試執行以下操作
SELECT ST_Union(rast)
FROM rasters;
你會立即被錯誤懲罰
錯誤:rt_raster_from_two_rasters:提供的兩個柵格沒有相同的對齊方式 SQL 狀態:XX000
這個相同的對齊方式是什麼,阻止你合併你珍貴的柵格?
為了合併柵格,它們需要位於相同的網格上。這表示它們必須具有相同的像素大小、相同的方向(傾斜)、相同的空間參考系統,並且它們的像素不能彼此切割,表示它們共享相同的全局像素網格。
如果你嘗試相同的查詢,但僅使用我們仔細放置在紐約的文字。
再次出現相同的錯誤。這些具有相同的空間參考系統,相同的像素大小,但仍然不夠好。因為它們的網格偏離了。
我們可以透過稍微移動左上角的 y 坐標來解決這個問題,然後再次嘗試。如果我們的網格以整數層級開始,因為我們的像素大小是整數,那麼像素將不會彼此切割。
UPDATE rasters SET rast = ST_SetUpperLeft(rast,
ST_UpperLeftX(rast)::integer,
ST_UpperLeftY(rast)::integer)
WHERE name LIKE '%New York';
SELECT ST_Union(rast ORDER BY name)
FROM rasters
WHERE name LIKE '%New York%';
瞧,它成功了,如果我們檢視,我們會看到類似這樣的東西

注意
如果你不清楚為什麼你的柵格沒有相同的對齊方式,你可以使用函數 ST_SameAlignment,它將比較 2 個柵格或一組柵格,並告訴你它們是否具有相同的對齊方式。如果你啟用了通知,通知會告訴你問題柵格有哪些問題。ST_NotSameAlignmentReason,而不是僅僅是通知,將會輸出原因。但是,它一次只能處理兩個柵格。
在 ST_Union(raster) 點陣函式與 ST_Union(geometry) 幾何函式之間,一個主要的差異在於前者允許一個名為 uniontype 的引數。如果您沒有指定,此引數預設會設定為 LAST,這表示在點陣像素值重疊的情況下,取用最後的點陣像素值。一般而言,在頻帶中被標記為無資料的像素會被忽略。
就像 PostgreSQL 中大多數的聚合函數一樣,您可以將 ORDER BY 子句作為函式呼叫的一部分,如同先前的範例所示。指定順序可讓您控制哪個點陣具有優先權。因此,在我們先前的範例中,Raster 優先於 Hello,因為 Raster 在字母順序上是最後一個。
請注意,如果交換順序
SELECT ST_Union(rast ORDER BY name DESC)
FROM rasters
WHERE name LIKE '%New York%';

那麼 Hello 就會優先於 Raster,因為 Hello 現在是最後疊加的。
FIRST 聯集類型與 LAST 相反。
但在某些情況下,LAST 可能不是正確的操作。假設我們的點陣代表來自兩個不同裝置的兩組不同觀測值。這些裝置測量相同的東西,而且我們不確定它們在交叉時哪個是正確的,所以我們想取結果的 MEAN(平均值)。我們會這樣做:
SELECT ST_Union(rast, 'MEAN')
FROM rasters
WHERE name LIKE '%New York%';
瞧,它成功了,如果我們檢視,我們會看到類似這樣的東西

因此,我們並非取優先,而是將兩種力混合。在 MEAN 聯集類型的情況下,沒有必要指定順序,因為結果會是重疊像素值的平均值。
請注意,對於幾何圖形,由於幾何圖形是向量,因此除了存在與否之外沒有值,所以在它們相交時如何組合兩個向量並沒有任何歧義。
點陣 ST_Union 的另一個我們略過的特性是,您應該傳回所有頻帶還是只傳回某些頻帶。當您沒有指定要聯集的頻帶時,ST_Union 會組合相同編號的頻帶,並使用 LAST 聯集策略。如果您有多個頻帶,這可能不是您想要的操作。也許您只想聯集第二個頻帶。在這種情況下,綠色頻帶,並且您想要像素值的計數。
SELECT ST_BandPixelType(ST_Union(rast, 2, 'COUNT'))
FROM rasters
WHERE name LIKE '%New York%';
st_bandpixeltype
------------------
32BUI
(1 row)
請注意,在 COUNT 聯集類型的情況下,它會計算已填入的像素數量並傳回該值,結果始終是 32BUI,類似於您在 SQL 中執行 COUNT 時,結果始終是 bigint,以容納大量計數。
在其他情況下,頻帶像素類型不會改變,並設定為最大值,如果數量超過類型的界限,則會四捨五入。為什麼會有人想計算在某個位置相交的像素?假設您的每個點陣都代表警察中隊和該區域的逮捕事件。每個值都可能代表不同的逮捕原因。您正在統計每個區域的逮捕數量,因此您只關心逮捕的計數。
或者,您可能想要對所有頻帶執行操作,但想要不同的策略。
SELECT ST_Union(rast, ARRAY[(1, 'MAX'),
(2, 'MEAN'),
(3, 'RANGE')]::unionarg[])
FROM rasters
WHERE name LIKE '%New York%';
使用 ST_Union 函式的 unionarg[] 變體,還可以讓您隨機調整頻帶的順序。
30.5.2. 利用 ST_Intersects 裁剪點陣¶
ST_Clip 函式是 PostGIS 點陣最廣泛使用的函式之一。主要原因是您需要檢查或操作的像素越多,處理速度就越慢。ST_Clip 會將您的點陣裁剪到感興趣的區域,因此您可以將操作隔離到該區域。
此函式也很特別,它利用幾何圖形的力量來協助點陣分析。為了減少 ST_Union 必須處理的像素數量,每個點陣都會先裁剪到我們感興趣的區域。
SELECT ST_Union( ST_Clip(r.rast, g.geom) )
FROM rasters AS r
INNER JOIN
ST_Buffer(ST_Point(586598, 4504816, 26918), 100 ) AS g(geom)
ON ST_Intersects(r.rast, g.geom)
WHERE r.name LIKE '%New York%';
此範例展示了多個函式協同運作。所使用的 ST_Intersects 函式是與 postgis_raster 一起封裝的,並且可以與 2 個點陣或一個點陣和一個幾何圖形相交。類似於幾何圖形的 ST_Intersects,點陣 ST_Intersects 可以利用點陣或幾何圖形表上的空間索引。
注意
預設情況下,ST_Clip 會排除像素的中心點不與幾何圖形相交的像素。這對於大型像素來說可能很煩人,您可能更喜歡改為在像素的任何部分接觸幾何圖形時包含該像素。PostGIS 3.5 中引入了 touched 引數。將您的 ST_Clip(r.rast, g.geom) 取代為 ST_Clip(r.rast, g.geom, touched => true),然後,任何以任何方式與您的幾何圖形相交的像素都會被包含在內。
30.6. 將點陣轉換為幾何圖形¶
點陣可以很容易地變形為幾何圖形。
30.6.1. 使用 ST_Polygon 建立點陣的多邊形¶
讓我們從先前的範例開始,但使用 ST_Polygon 函式將其轉換為多邊形。
SELECT ST_Polygon(ST_Union( ST_Clip(r.rast, g.geom) ))
FROM rasters AS r
INNER JOIN
ST_Buffer(ST_Point(586598, 4504816, 26918), 100 ) AS g(geom)
ON ST_Intersects(r.rast, g.geom)
WHERE r.name LIKE '%New York%';
如果您在 pgAdmin 中按一下幾何圖形檢視器,您就可以看到它完整且無任何漏洞的樣子。
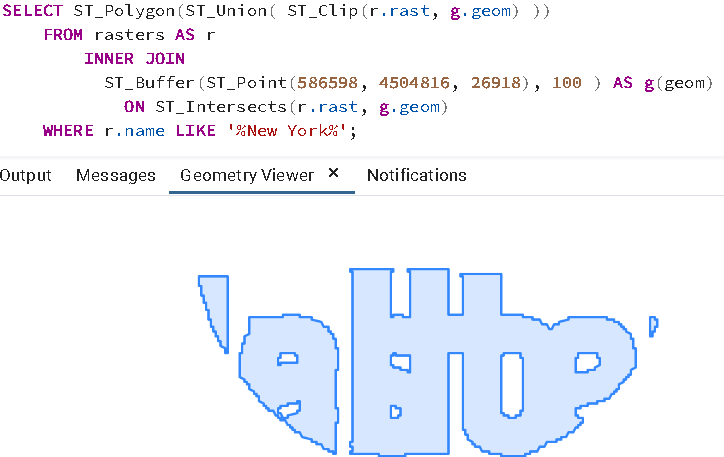
ST_Polygon 會考慮特定頻帶中所有具有值(非無資料)的像素,並將其轉換為幾何圖形。如同點陣中的許多其他函式,ST_Polygon 只會考慮 1 個頻帶。如果沒有指定頻帶,則只會考慮第一個頻帶。
30.6.2. 使用 ST_PixelAsPolygons 取得點陣的像素矩形¶
另一個常用的函式是 ST_PixelAsPolygons 函式。您很少會在沒有先裁剪的情況下對大型點陣使用 ST_PixelAsPolygons,因為您最終會得到數百萬行,每行對應一個像素。
ST_PixelAsPolygons 會傳回一個包含 geom、val、x 和 y 的表格。其中 x 是欄號,y 是點陣中的列號。
與其他點陣函式類似,ST_PixelAsPolygons 一次處理一個頻帶,如果沒有指定頻帶,則處理頻帶 1。它也預設只傳回具有值的像素。
SELECT gv.*
FROM rasters AS r
CROSS JOIN LATERAL ST_PixelAsPolygons(rast) AS gv
WHERE r.name LIKE '%New York%'
LIMIT 10;
輸出:
如果我們使用幾何圖形檢視器檢查,我們將看到:
如果我們想要所有頻帶的所有像素,我們需要執行如下所示的操作。請注意此範例與先前的差異。
1. 設定 exclude_nodata_value 以確保傳回所有像素,以便我們的呼叫集傳回相同數量的行。函式輸出的行會自然地以相同的順序排列。
2. 使用 PostgreSQL ROWS FROM 建構子,並使用名稱為函式輸出中的每一組欄建立別名。例如,頻帶 1 的欄 (geom, val, x, y) 會重新命名為 g1、v1、x1、x2
SELECT pp.g1, pp.v1, pp.v2, pp.v3
FROM rasters AS r
CROSS JOIN LATERAL
ROWS FROM (
ST_PixelAsPolygons(rast, 1, exclude_nodata_value => false ),
ST_PixelAsPolygons(rast, 2, exclude_nodata_value => false),
ST_PixelAsPolygons(rast, 3, exclude_nodata_value => false )
) AS pp(g1, v1, x1, y1,
g2, v2, x2, y2,
g3, v3, x3, y3 )
WHERE r.name LIKE '%New York%'
AND ( pp.v1 = 0 OR pp.v2 > 0 OR pp.v3 > 0) ;
注意
我們在這些範例中使用 CROSS JOIN LATERAL 是因為我們希望明確指出我們正在做什麼。由於這些都是設定傳回函式,因此您可以使用 , 取代 CROSS JOIN LATERAL 作為簡寫。我們將在下一組範例中使用 ,
30.6.3. 使用 ST_DumpAsPolygons 傾印多邊形¶
點陣還引入了另一個稱為 geomval 的複合類型。將 geomval 視為幾何圖形和點陣的後代。它包含幾何圖形,並且包含像素值。
您會發現有幾個點陣函式會傳回 geomval。
一個常用的輸出 geomval 的函式是 ST_DumpAsPolygons,它會將一組具有相同值的連續像素傳回為多邊形。同樣地,這預設只會檢查頻帶 1,並排除無資料值,除非您覆寫。此範例只會從頻帶 2 中選取多邊形。您也可以將篩選器套用至值。在大多數使用案例中,ST_DumpAsPolygons 比 ST_PixelAsPolygons 更好,因為它會傳回更少的行。
這會輸出 6 行,並傳回對應於「Raster」字母的多邊形。
SELECT gv.geom , gv.val
FROM rasters AS r,
ST_DumpAsPolygons(rast, 2) AS gv
WHERE r.name LIKE '%New York%'
AND gv.val = 100;
請注意,它不會傳回單一幾何圖形,因為它會找到具有相同值且形成多邊形的連續像素集。即使這些值都相同,它們也不是連續的。

產生更複雜幾何圖形的一個常見方法是依值分組並聯集。
SELECT ST_Union(gv.geom) AS geom , gv.val
FROM rasters AS r,
ST_DumpAsPolygons(rast, 2) AS gv
WHERE r.name LIKE '%New York%'
GROUP BY gv.val;
這會傳回 2 列,對應於「Raster」和「Hello」這兩個詞。
30.7. 統計資料¶
了解點陣最重要的事是,它們是用於將資料儲存在陣列中的統計工具,而您可能剛好可以在螢幕上讓它們看起來很漂亮。
您可以在 點陣頻帶統計資料 中找到這些統計函式的選單。
30.7.1. ST_SummaryStatsAgg 和 ST_SummaryStats¶
想要一組或多個點陣的所有統計資料,請使用函式 ST_SummaryStatsAgg。
此查詢大約需要 10 秒,並提供整個表格的摘要
SELECT (ST_SummaryStatsAgg(rast, 1, true, 1)).* AS sa
FROM o_3_nyc_dem;
輸出:
count | sum | mean | stddev | min | max
-----------+------------+------------------+------------------+-----+-----
246794100 | 4555256024 | 18.4577184948911 | 39.4416860598687 | 0 | 411
(1 row)
這告訴我們有很多像素,且我們的最大高度為 411 英尺。
如果您已建立概觀,且只需要粗略估計最小值、最大值和平均值,請使用您的其中一個概觀。下一個查詢會傳回與先前查詢大致相同的最小值、最大值和平均值,但大約只需要 1 秒而不是 10 秒。
SELECT (ST_SummaryStatsAgg(rast, 1, true, 1)).* AS sa
FROM o_3_nyc_dem ;
現在有了這點資訊,我們就可以問更多問題。
30.7.2. ST_Histogram¶
通常您不會想要整個表格的統計資料,而是只想要特定區域的統計資料,在這種情況下,您也會想要使用我們的好朋友 ST_Intersects 和 ST_Clip。如果您還需要一個沒有聚合版本的點陣統計函式,則會想要連帶使用 ST_Union。
在下一個範例中,我們將使用不同的統計函式 ST_Histogram,它沒有聚合等效項,而且對於此特定變體而言,它是一個設定傳回函式。我們正在使用與先前一些範例相同的感興趣區域,但我們也需要使用幾何圖形 ST_Transform 將我們的紐約州平面公尺幾何圖形轉換為我們的紐約市平面英尺點陣。轉換幾何圖形的效能幾乎總是比點陣更高,如果您的幾何圖形只有一個,則更是如此。
SELECT (ST_Quantile( ST_Union( ST_Clip(r.rast, g.geom) ), ARRAY[0.25,0.50,0.75, 1.0] )).*
FROM nyc_dem AS r
INNER JOIN
ST_Transform(
ST_Buffer(ST_Point(586598, 4504816, 26918), 100 ),
2263) AS g(geom)
ON ST_Intersects(r.rast, g.geom);
上面的查詢會在 60 毫秒內完成並輸出:
quantile | value
----------+-------
0.25 | 52
0.5 | 57
0.75 | 68
1 | 78
(4 rows)
30.8. 建立衍生點陣¶
PostGIS 光柵資料包裝了許多用於編輯光柵的功能。這些功能既可用於編輯,也可用於建立衍生光柵資料集。您可以在光柵編輯器和光柵管理中找到這些功能的列表。
30.8.1. 使用 ST_Transform 轉換光柵¶
我們的大部分資料都採用紐約州平面公尺 (SRID: 26918),但是我們的 DEM 光柵資料集採用紐約州平面英尺 (SRID: 2263)。為了獲得最簡便的工作流程,我們需要核心資料集採用相同的空間參考系統。
光柵 ST_Transform 是最適合這項工作的函數。
為了建立一個採用紐約州平面公尺的新 nyc dem 資料集,我們將執行以下操作
CREATE TABLE nyc_dem_26918 AS
WITH ref AS (SELECT ST_Transform(rast,26918) AS rast
FROM nyc_dem LIMIT 1)
SELECT r.rid, ST_Transform(r.rast, ref.rast) AS rast, r.filename
FROM nyc_dem AS r, ref;
以上操作在我的系統上大約花了 1.5 分鐘。對於較大的資料集,將會花費更長的時間。
上述範例使用了 ST_Transform 光柵函數的兩種變體。第一種是取得一個參考光柵,用於轉換其他光柵圖塊,以保證所有圖塊具有相同的對齊方式。請注意,第二種 ST_Transform 的變體甚至不接受輸入 SRID。這是因為 SRID 以及所有像素比例和區塊大小都是從參考光柵讀取的。如果您使用 ST_Transform(rast, srid) 形式,那麼您的所有光柵都可能出現不同的對齊方式,使得無法對它們應用諸如 ST_Union 之類的操作。
上述 ST_Transform 方法的唯一問題是,當您轉換時,轉換後的光柵通常存在於其他圖塊中。如果您仔細觀察上述輸出,並輸出光柵的凸包,您會在下一個範例中看到邊界周圍惱人的重疊。
SELECT rast::geometry
FROM nyc_dem_26918
ORDER BY rid
LIMIT 100;
在 pgAdmin 中查看會像這樣

30.8.2. 使用 ST_MakeEmptyCoverage 建立均勻平鋪的光柵¶
一種更好的方法,雖然速度稍慢,是使用 ST_MakeEmptyCoverage 從頭開始定義您自己的覆蓋圖塊結構,然後找到每個新圖塊的相交圖塊,並對這些圖塊進行 ST_Union,然後使用 ST_Transform(ref, ST_Union…) 來建立每個圖塊。
為此,我們將使用許多我們之前學過的功能。
DROP TABLE IF EXISTS nyc_dem_26918;
CREATE TABLE nyc_dem_26918 AS
SELECT ROW_NUMBER() OVER(ORDER BY t.rast::geometry) AS rid,
ST_Union(ST_Clip( ST_Transform( r.rast, t.rast, 'Bilinear' ), t.rast::geometry ), 'MAX') AS rast
FROM (SELECT ST_Transform(
ST_SetSRID(ST_Extent(rast::geometry),2263)
, 26918) AS geom
FROM nyc_dem
) AS g, ST_MakeEmptyCoverage(tilewidth => 256, tileheight => 256,
width => (ST_XMax(g.geom) - ST_XMin(g.geom))::integer,
height => (ST_YMax(g.geom) - ST_YMin(g.geom))::integer,
upperleftx => ST_XMin(g.geom),
upperlefty => ST_YMax(g.geom),
scalex => 3.048,
scaley => -3.048,
skewx => 0., skewy => 0., srid => 26918) AS t(rast)
INNER JOIN nyc_dem AS r
ON ST_Transform(t.rast::geometry, 2263) && r.rast
GROUP BY t.rast;
重複與先前相同的練習
SELECT rast::geometry
FROM nyc_dem_26918
ORDER BY rid
LIMIT 100;
在 pgAdmin 中查看,我們不再有重疊

在我的系統上,這花了約 10 分鐘並傳回 3879 列。建立表格後,我們將希望像往常一樣添加空間索引、主索引鍵和約束,如下所示
ALTER TABLE nyc_dem_26918
ADD CONSTRAINT pk_nyc_dem_26918 PRIMARY KEY(rid);
CREATE INDEX ix_nyc_dem_26918_st_convexhull_gist
ON nyc_dem_26918 USING gist( ST_ConvexHull(rast) );
SELECT AddRasterConstraints('nyc_dem_26918'::name, 'rast'::name);
ANALYZE nyc_dem_26918;
對於這個資料集,應該會在 2 分鐘內完成。
30.8.3. 使用 ST_CreateOverview 建立概觀表格¶
與我們的原始資料集一樣,擁有概觀表格將有助於加速某些操作的效能。ST_CreateOverview 是一個適合該用途的函數。如果您在 raster2pgsql 載入期間忽略建立概觀,或者您決定需要更多概觀,您也可以使用 ST_CreateOverview 來建立概觀。
我們將使用此程式碼建立與原始程式碼相同的層級 2 和 3 概觀。
SELECT ST_CreateOverview('nyc_dem_26918'::regclass, 'rast', 2);
SELECT ST_CreateOverview('nyc_dem_26918'::regclass, 'rast', 3);
這個過程遺憾地需要一段時間,而且您擁有的列數越多,所需的時間就越長,因此請耐心等待。對於這個資料集,概觀係數 2 大約需要 3-5 分鐘,而概觀係數 3 則需要 1 分鐘。
ST_CreateOverView 函數還會添加所需的約束,以便這些欄位以完整詳細資訊顯示在 raster_columns 和 raster_overviews 目錄中。但是它不會將索引新增至這些欄位,也不會新增 rid 欄位。除非您需要主索引鍵進行編輯,否則 rid 欄位可能不是必需的。您可能需要一個索引,您可以使用以下程式碼建立索引
CREATE INDEX ix_o_2_nyc_dem_26918_st_convexhull_gist
ON o_2_nyc_dem_26918 USING gist( ST_ConvexHull(rast) );
CREATE INDEX ix_o_3_nyc_dem_26918_st_convexhull_gist
ON o_3_nyc_dem_26918 USING gist( ST_ConvexHull(rast) );
注意
ST_CreateOverview 有一個可選參數,用於表示取樣方法。如果未指定,則會使用預設的 NearestNeighbor,這通常是計算速度最快的方法,但可能不是最理想的方法。重新取樣方法不在本工作坊的範圍內。
30.9. 光柵和幾何圖形的交集¶
有幾個常用的函數可用於計算光柵和幾何圖形的交集。我們已經看到 ST_Clip 在執行,它會傳回光柵和幾何圖形的交集作為光柵,但是還有其他函數。對於點資料,最常用的是 ST_Value,然後還有 ST_Intersection,它有數個過載,有些會傳回光柵,有些則會傳回一組 geomval。
30.9.1. 幾何點的像素值¶
如果您需要根據數個臨時幾何點的交集傳回光柵的值,您可以使用 ST_Value 或其最近的相關函數 ST_NearestValue。
SELECT g.geom, ST_Value(r.rast, g.geom) AS elev
FROM nyc_dem_26918 AS r
INNER JOIN
(SELECT id, geom
FROM nyc_homicides
WHERE weapon = 'gun') AS g
ON r.rast && g.geom;
這個範例大約花費 1 秒鐘傳回 2444 列。如果您使用 ST_Intersects 而不是 &&,則這個過程將花費大約 3 秒鐘。ST_Intersects 速度較慢的原因是,它在某些情況下會執行額外的重新檢查,逐個像素地檢查。如果您期望所有點都以資料形式顯示在光柵集中,並且光柵表示覆蓋範圍(一組連續的不重疊光柵圖塊),則 && 通常是更快速的選項。
如果您的光柵資料不是密集分佈的,或者您有重疊的光柵(例如,它們表示時間上的不同觀察結果),或者它們是傾斜的(非軸對齊),那麼使用 ST_Intersects 來篩除錯誤的肯定結果是有優勢的。
30.9.2. ST_Intersection 光柵樣式¶
正如您可以使用 ST_Intersection 計算兩個幾何圖形的交集一樣,您可以使用 光柵 ST_Intersection 計算兩個光柵或光柵與幾何圖形的交集。
您從此操作中獲得的是兩種不同的事物
將幾何圖形與光柵相交,您將獲得一組 geomval 後代。也許一個,但通常是許多個。
將 2 個光柵相交,您將獲得一個單一的 光柵 回應。
光柵交集和幾何圖形交集的黃金法則是,參與的雙方都必須具有相同的空間參考系統。對於光柵/光柵,它們還必須具有相同的對齊方式。
這是一個範例,可以回答您可能一直好奇的問題。如果我們將海拔高度分成 5 個海拔值區間,哪個海拔範圍會導致最多槍枝致死事件?根據我們之前的彙總統計資料,我們知道 0 是 nyc dem 資料集中最低的海拔值,而 411 是最高的海拔值,因此我們將其用作 width_bucket 呼叫的最小值和最大值。
SELECT ST_Transform(ST_Union(gv.geom),4326) AS geom ,
MIN(gv.val) AS min_elev, MAX(gv.val) AS max_elev,
count(g.id) AS count_guns
FROM nyc_dem_26918 AS r
INNER JOIN nyc_homicides AS g
ON ST_Intersects(r.rast, g.geom)
CROSS JOIN
ST_Intersection( g.geom,
ST_Clip(r.rast,ST_Expand(g.geom, 4) )
) AS gv
WHERE g.weapon = 'gun'
GROUP BY width_bucket(gv.val, 0, 411, 5)
ORDER BY width_bucket(gv.val, 0, 411, 5);
槍枝謀殺與海拔高度之間是否存在重要的關聯?可能沒有。
讓我們看看光柵/光柵交集
SELECT ST_Intersection(r1.rast, 1, r2.rast, 1, 'BAND1')
FROM nyc_dem_26918 AS r1
INNER JOIN
rasters AS r2 ON ST_Intersects(r1.rast,1, r2.rast, 1);
我們得到的是兩列包含 NULL 的資料列,如果您將 PostgreSQL 設定為顯示通知,您將會看到
通知:提供的兩個光柵沒有相同的對齊方式。傳回 NULL
為了修正這個問題,我們可以讓其中一個光柵與另一個光柵對齊,就像它使用 ST_Resample 出來時一樣。
SELECT ST_Intersection(r1.rast, 1,
ST_Resample( r2.rast, r1.rast ), 1,
'BAND1')
FROM nyc_dem_26918 AS r1
INNER JOIN
rasters AS r2 ON ST_Intersects(r1.rast,1, r2.rast, 1);
讓我們也將其整合到單一統計記錄中
SELECT (
ST_SummaryStatsAgg(
ST_Intersection(r1.rast, 1,
ST_Resample( r2.rast, r1.rast ), 1, 'BAND1'),
1, true)
).*
FROM nyc_dem_26918 AS r1
INNER JOIN
rasters AS r2 ON ST_Intersects(r1.rast,1, r2.rast, 1);
輸出
count | sum | mean | stddev | min | max
-------+-------+-----------------+------------------+-----+-----
2075 | 99536 | 47.969156626506 | 9.57974836865737 | 33 | 62
(1 row)
30.10. 地圖代數函數¶
地圖代數是指您可以對像素值進行數學運算的想法。先前涵蓋的 ST_Union 和 ST_Intersection 函數是地圖代數的特殊快速情況。然後還有 ST_MapAlgebra 系列函數,允許您定義自己的複雜數學運算,但代價是效能降低。
人們習慣於跳到 ST_MapAlgebra,可能是因為這個名稱聽起來很酷而且很複雜。誰不想告訴他們的朋友?*我正在使用一個名為 ST_MapAlgebra 的函數。*我的建議是,在您拿出那把散彈槍之前,先探索其他函數。您的生活會更簡單,您的效能會提高 100 倍,而且您的程式碼會更短。
在我們展示 ST_MapAlgebra 之前,我們將探索屬於 地圖代數 系列函數的其他函數,並且通常具有比 ST_MapAlgebra 更好的效能。
30.10.1. 使用 ST_Reclass 重新分類您的光柵¶
一個經常被忽略的類地圖代數函數是 ST_Reclass 函數,它在幕後等待有人發現它可以提供的力量和速度。
ST_Reclass 做什麼?顧名思義,它會根據最簡化的範圍代數重新分類您的像素值。
讓我們重新審視我們的 NYC Dems。也許我們只關心將海拔高度分類為 1) 低、2) 中、3) 高和 4) 非常高。我們不需要 411 個值,我們只需要 4 個值。話雖如此,讓我們進行一些重新分類。
分類方案受 重新分類運算式 的約束。
WITH r AS ( SELECT ST_Union(newrast) As rast
FROM nyc_dem_26918 AS r
INNER JOIN ST_Buffer(ST_Point(586598, 4504816, 26918), 1000 ) AS g(geom)
ON ST_Intersects( r.rast, g.geom )
CROSS JOIN ST_Reclass( ST_Clip(r.rast,g.geom), 1,
'[0-10):1, [10-50):2, [50-100):3,[100-:4','4BUI',0) AS newrast
)
SELECT SUM(ST_Area(gv.geom)::numeric(10,2)) AS area, gv.val
FROM r, ST_DumpAsPolygons(rast) AS gv
GROUP BY gv.val
ORDER BY gv.val;
輸出
area | val
------------+-----
6754.04 | 1
1753117.51 | 2
1355232.37 | 3
1848.75 | 4
(4 rows)
如果這是我們偏好的分類方案,我們可以建立一個新表格,使用 ST_Reclass 重新計算每個圖塊。
30.10.2. 使用 ST_ColorMap 為您的光柵著色¶
ST_ColorMap 函式是另一個類似於地圖代數的函式,它會重新分類您的像素值。不同的是,它會建立波段。它會將單一波段的柵格(例如我們的 DEM)轉換為視覺上更具表現力的 3 或 4 個波段柵格。
如果您不想費心創建自己的色帶,可以使用以下內建的色帶之一。
SELECT ST_ColorMap( ST_Union(newrast), 'bluered') As rast
FROM nyc_dem_26918 AS r
INNER JOIN
ST_Buffer(
ST_Point(586598, 4504816, 26918), 1000
) AS g(geom)
ON ST_Intersects( r.rast, g.geom)
CROSS JOIN ST_Clip(rast, g.geom) AS newrast;
看起來像這樣

顏色越藍表示海拔越低,顏色越紅表示海拔越高。
