22. 更多的空間連接¶
在上一個章節中,我們看過 ST_Centroid(geometry) 和 ST_Union([geometry]) 函式,以及一些簡單範例。在本章節中,我們將對它們進行更精細的操作。
22.1. 建立人口普查區塊資料表¶
在工作坊 \data\ 目錄中,有一個檔案包含屬性資料,但沒有幾何, nyc_census_sociodata.sql。該資料表包含紐約市的有趣社會經濟資料:上下班時間、所得、和教育程度。只有一個問題。資料是根據「人口普查區塊」進行摘要,我們沒有人口普查區塊的空間資料!
在本章節中,我們將
載入
nyc_census_sociodata.sql資料表為人口普查區塊建立一個空間資料表
將屬性資料與空間資料結合
使用我們的最新資料進行一些分析
22.1.1. 載入 nyc_census_sociodata.sql¶
在 PgAdmin 中開啟 SQL 查詢視窗
從功能表中選擇 檔案->開啟,並瀏覽至
nyc_census_sociodata.sql檔案按下「執行查詢」按鈕
如果您按下 PgAdmin 中的「重整」按鈕,資料表清單中現在應該會包含一個
nyc_census_sociodata資料表
22.1.2. 建立人口普查區塊資料表¶
正如我們在上一個章節中所見,我們可以透過 blkid 金鑰子字串摘要來建立更高級的幾何,從普查區塊。為了取得人口普查區塊,我們需要根據 blkid 的前 11 個字元來進行群組摘要。
360610001001001 = 36 061 000100 1 001
36 = State of New York
061 = New York County (Manhattan)
000100 = Census Tract
1 = Census Block Group
001 = Census Block
使用 ST_Union 彙總來建立新的資料表
-- Make the tracts table
CREATE TABLE nyc_census_tract_geoms AS
SELECT
ST_Union(geom) AS geom,
SubStr(blkid,1,11) AS tractid
FROM nyc_census_blocks
GROUP BY tractid;
-- Index the tractid
CREATE INDEX nyc_census_tract_geoms_tractid_idx
ON nyc_census_tract_geoms (tractid);
22.1.3. 將屬性與空間資料結合¶
使用標準屬性連接,將區塊幾何資料表與區塊屬性資料表結合
-- Make the tracts table
CREATE TABLE nyc_census_tracts AS
SELECT
g.geom,
a.*
FROM nyc_census_tract_geoms g
JOIN nyc_census_sociodata a
ON g.tractid = a.tractid;
-- Index the geometries
CREATE INDEX nyc_census_tract_gidx
ON nyc_census_tracts USING GIST (geom);
22.1.4. 回答一個有趣的問題¶
回答一個有趣的問題!「列出前 10 名依擁有碩士學位的人口比例排列的紐約社區」。
SELECT
100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total) AS graduate_pct,
n.name, n.boroname
FROM nyc_neighborhoods n
JOIN nyc_census_tracts t
ON ST_Intersects(n.geom, t.geom)
WHERE t.edu_total > 0
GROUP BY n.name, n.boroname
ORDER BY graduate_pct DESC
LIMIT 10;
我們加總我們感興趣的統計資料,然後在最後將它們除以總計。為了避免除以零的錯誤,我們不麻煩引進人口數為零的區域。
graduate_pct | name | boroname
--------------+-------------------+-----------
47.6 | Carnegie Hill | Manhattan
42.2 | Upper West Side | Manhattan
41.1 | Battery Park | Manhattan
39.6 | Flatbush | Brooklyn
39.3 | Tribeca | Manhattan
39.2 | North Sutton Area | Manhattan
38.7 | Greenwich Village | Manhattan
38.6 | Upper East Side | Manhattan
37.9 | Murray Hill | Manhattan
37.4 | Central Park | Manhattan
備註
紐約的地理學家一定會對「Flatbush」出現在這個受教育程度過高的社區清單上感到疑惑。答案將在下一章中討論。
22.2. 多邊形/多邊形連線¶
我們使用 ST_Intersects(geometry_a, geometry_b) 函式在我們的有趣查詢(在 回答一個有趣的問題 中)確定每個社區摘要中要包含哪些人口普查區的多邊形。這會導致一個問題:如果某個區剛好位於兩個社區的邊界上會怎樣?它會和兩個區相交,因此會同時包含在兩個彙總統計資料中。
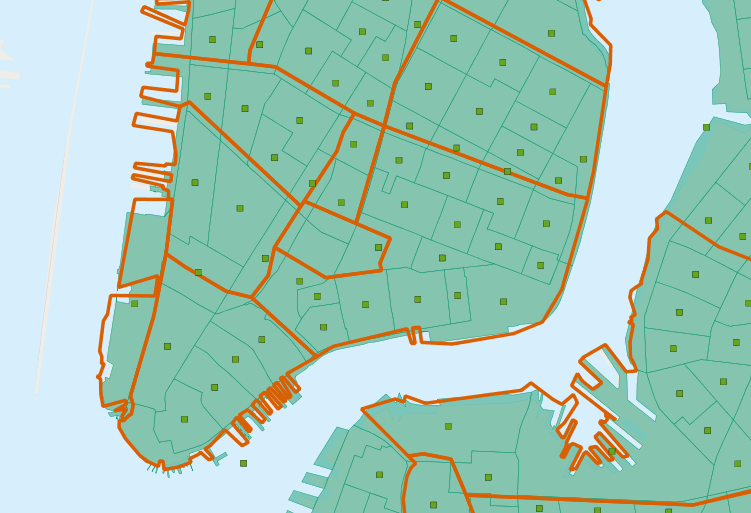
要避免這種重複計數,有兩種方法
簡單的方法是確保每個區僅計入一個彙總區域中(使用 ST_Centroid(geometry))
複雜的方法是將交會的區劃分在邊界上(使用 ST_Intersection(geometry,geometry))
以下是使用簡單方法避免在我們的大學教育查詢中重複計數的範例
SELECT
100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total) AS graduate_pct,
n.name, n.boroname
FROM nyc_neighborhoods n
JOIN nyc_census_tracts t
ON ST_Contains(n.geom, ST_Centroid(t.geom))
WHERE t.edu_total > 0
GROUP BY n.name, n.boroname
ORDER BY graduate_pct DESC
LIMIT 10;
請注意,查詢現在執行需要較長的時間,因為必須對每個人口普查區執行 ST_Centroid 函式。
graduate_pct | name | boroname
--------------+---------------------+-----------
48.0 | Carnegie Hill | Manhattan
44.2 | Morningside Heights | Manhattan
42.1 | Greenwich Village | Manhattan
42.0 | Upper West Side | Manhattan
41.4 | Tribeca | Manhattan
40.7 | Battery Park | Manhattan
39.5 | Upper East Side | Manhattan
39.3 | North Sutton Area | Manhattan
37.4 | Cobble Hill | Brooklyn
37.4 | Murray Hill | Manhattan
避免重複計數會改變結果!
22.2.1. Flatbush 呢?¶
特別是,Flatbush 社區已從清單中刪除。原因可以從我們表格中 Flatbush 社區的地圖中更仔細地觀察中得知。
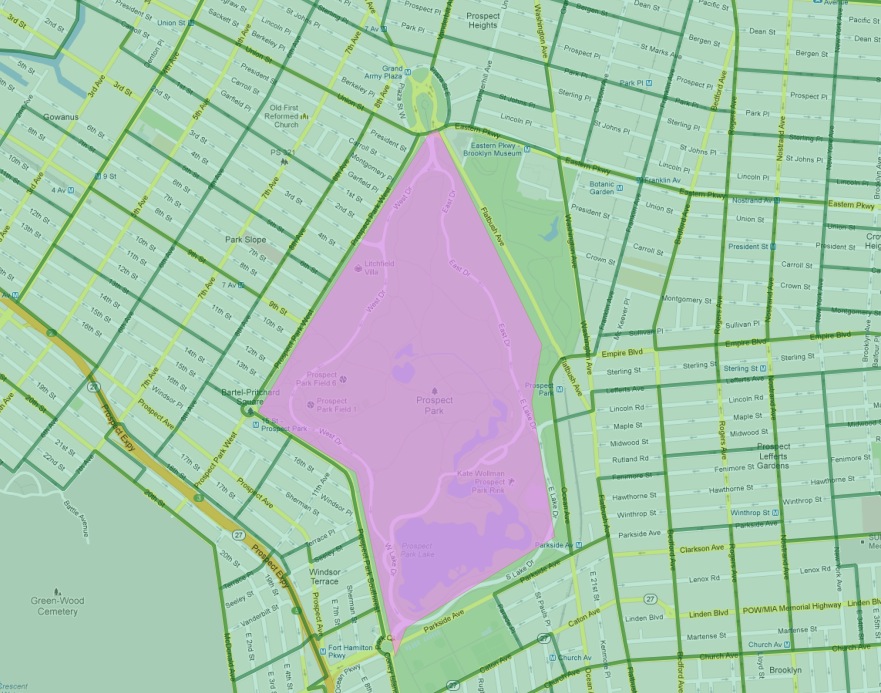
根據我們的資料來源定義,Flatbush 實際上並非傳統意義上的社區,因為它僅涵蓋了展望公園的面積。該區域的人口普查區自然只記錄了零位居民。不過,社區邊界確實刮到了公園北側(在士紳化的 Park Slope 社區)邊界上的其中一個昂貴的人口普查區。在使用多邊形/多邊形測試時,這個單獨的區域被加入到否則空無一物的 Flatbush 中,導致該查詢的分數非常高。
22.3. 大範圍半徑距離連線¶
一個很好玩的查詢是:「接近(500 公尺以內)地鐵站的人員通勤時間如何不同於遠離地鐵站的人員?」
然而,這個問題會遇到重複計算的問題:很多人會同時接近多個地鐵站,500 公尺以內。比較紐約的人口
SELECT Sum(popn_total)
FROM nyc_census_blocks;
8175032
與紐約 500 公尺以內地鐵站人口
SELECT Sum(popn_total)
FROM nyc_census_blocks census
JOIN nyc_subway_stations subway
ON ST_DWithin(census.geom, subway.geom, 500);
10855873
靠近地鐵的人比一般人多!很明顯地,我們的簡單 SQL 會產生一個很大的重複計算錯誤。您可以查看緩衝地鐵的圖片,了解問題。
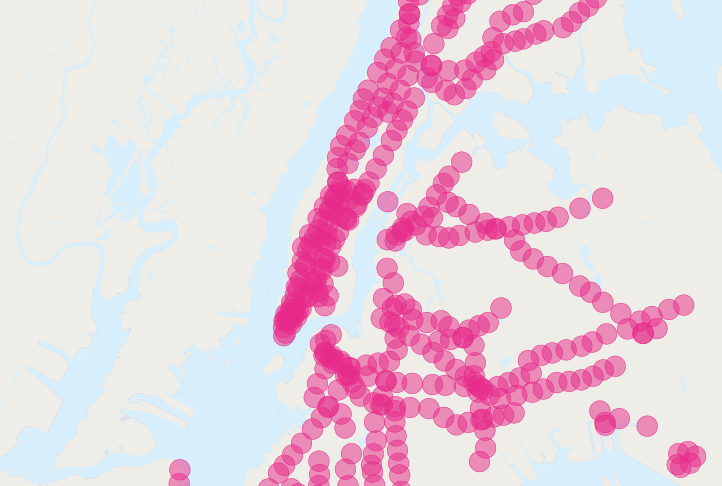
解決方法是確保我們在將資料區塊傳遞到查詢的摘要部分之前,僅有明確資料區塊。我們可以透過將查詢區分為一個子查詢(尋找明確的區塊),並包裹在摘要查詢中(傳回我們的答案),來達成目標
WITH distinct_blocks AS (
SELECT DISTINCT ON (blkid) popn_total
FROM nyc_census_blocks census
JOIN nyc_subway_stations subway
ON ST_DWithin(census.geom, subway.geom, 500)
)
SELECT Sum(popn_total)
FROM distinct_blocks;
5005743
這樣就好了!因此超過一半的紐約人口都在距離地鐵 500 公尺(約步行 5-7 分鐘)的範圍內。
