15. 空間索引¶
回想一下,空間索引是空間資料庫的三個關鍵功能之一。索引使得在大型資料集上使用空間資料庫成為可能。如果沒有索引,任何對要素的搜尋都需要對資料庫中的每個記錄進行「循序掃描」。索引通過將資料組織成一個搜尋樹來加速搜尋,可以快速遍歷該搜尋樹以找到特定記錄。
空間索引是 PostGIS 最重要的資產之一。在先前的範例中,建立空間連接需要比較整個表格。這可能會非常耗費成本:在沒有索引的情況下,連接兩個各包含 10,000 筆記錄的表格將需要 100,000,000 次比較;而使用索引,成本可能會低至 20,000 次比較。
我們的資料載入檔案已經包含所有表格的空間索引,因此為了展示索引的效用,我們必須先移除它們。
讓我們在 nyc_census_blocks 上執行一個查詢,不使用我們的空間索引。
我們的第一步是移除索引。
DROP INDEX nyc_census_blocks_geom_idx;
注意
DROP INDEX 語句從資料庫系統中刪除現有的索引。有關更多資訊,請參閱 PostgreSQL 文件。
現在,觀察 pgAdmin 查詢視窗右下角的「計時」計量表,並執行以下查詢。我們的查詢搜尋每個普查區塊,以識別包含以「B」開頭的地鐵站的區塊。
SELECT count(blocks.blkid)
FROM nyc_census_blocks blocks
JOIN nyc_subway_stations subways
ON ST_Contains(blocks.geom, subways.geom)
WHERE subways.name LIKE 'B%';
count
---------------
46
nyc_census_blocks 表格非常小(只有幾千筆記錄),因此即使沒有索引,在我的測試電腦上,查詢也僅需 300 毫秒。
現在將空間索引重新加入,然後再次執行查詢。
CREATE INDEX nyc_census_blocks_geom_idx
ON nyc_census_blocks
USING GIST (geom);
注意
USING GIST 子句告訴 PostgreSQL 在建立索引時使用通用索引結構 (GIST)。如果您在建立索引時收到類似 ERROR: index row requires 11340 bytes, maximum size is 8191 的錯誤,則您可能忘記加入 USING GIST 子句。
在我的測試電腦上,時間降至 50 毫秒。表格越大,索引查詢的相對速度改進就越大。
15.1. 空間索引如何運作¶
標準資料庫索引基於被索引的列的值建立一個分層樹狀結構。空間索引略有不同 – 它們無法索引幾何要素本身,而是索引要素的邊界框。
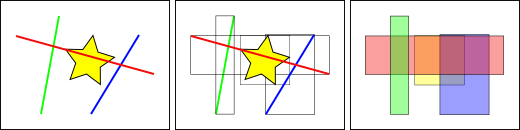
在上圖中,與黃色星形相交的線條數量是 一條,即紅線。但與黃色方塊相交的要素邊界框是 兩個,即紅色和藍色。
資料庫有效回答「哪些線條與黃色星形相交」問題的方式是,首先使用索引(速度非常快)回答「哪些方塊與黃色方塊相交」問題,然後僅針對第一次測試返回的那些要素執行「哪些線條與黃色星形相交」的精確計算。
對於大型表格,這種「兩階段」系統,即首先評估近似索引,然後執行精確測試,可以大幅減少回答查詢所需的計算量。
PostGIS 和 Oracle Spatial 都共享相同的「R 樹」1空間索引結構。R 樹將資料分解為矩形、子矩形和子子矩形等。它是一種自我調整的索引結構,可以自動處理可變資料密度、不同程度的物件重疊和物件大小。

15.2. 使用空間索引的函數¶
只有一部分函數會在有空間索引可用的情況下自動使用空間索引。
前四個是在查詢中最常用的,而 ST_DWithin 對於執行「在一定距離內」或「在一定半徑內」的樣式查詢非常重要,同時仍能從索引中獲得效能提升。
為了將索引加速功能添加到此列表中沒有的其他函數(最常見的是 ST_Relate),請加入如下所述的僅限索引的子句。
15.3. 僅限索引的查詢¶
PostGIS 中大多數常用函數(ST_Contains、ST_Intersects、ST_DWithin 等)會自動包含索引篩選器。但某些函數(例如,ST_Relate)不包含索引篩選器。
要使用索引進行邊界框搜尋(且不進行篩選),請使用 && 運算子。對於幾何圖形,&& 運算子表示「邊界框重疊或接觸」,這與數字的 = 運算子表示「值相同」的方式相同。
讓我們比較一個用於計算「西村」人口的僅限索引的查詢和一個更精確的查詢。使用 &&,我們的僅限索引的查詢如下所示:
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON neighborhoods.geom && blocks.geom
WHERE neighborhoods.name = 'West Village';
49821
現在,讓我們使用更精確的 ST_Intersects 函數執行相同的查詢。
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON ST_Intersects(neighborhoods.geom, blocks.geom)
WHERE neighborhoods.name = 'West Village';
26718
答案低得多!第一個查詢總計了每個邊界框與鄰近地區的邊界框相交的區塊;第二個查詢僅總計與鄰近地區本身相交的區塊。
15.4. 分析¶
PostgreSQL 查詢規劃器會智慧地選擇何時使用或不使用索引來評估查詢。違反直覺的是,執行索引搜尋並不總是更快:如果搜尋將返回表格中的每個記錄,則遍歷索引樹以取得每個記錄實際上會比從頭開始循序讀取整個表格要慢。
僅知道查詢矩形的大小不足以確定查詢會返回大量還是少量記錄。如下所示,紅色方塊很小,但將比藍色方塊返回更多的記錄。
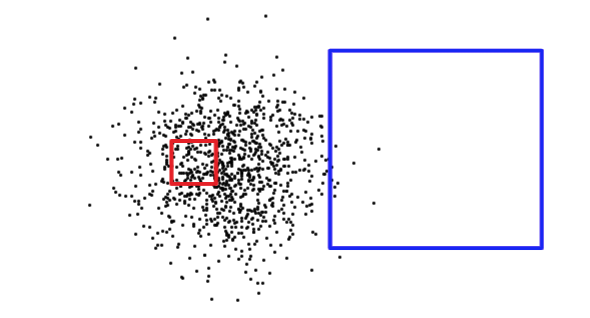
為了找出它正在處理的情況(讀取表格的一小部分還是讀取表格的很大一部分),PostgreSQL 會保留有關每個索引表格列中資料分佈的統計資訊。預設情況下,PostgreSQL 會定期收集統計資訊。但是,如果您在短時間內大幅變更表格內容,則統計資訊將不是最新的。
為了確保統計資訊與您的表格內容相符,建議在表格中大量載入和刪除資料後執行 ANALYZE 命令。這會強制統計系統收集所有索引列的資料。
ANALYZE 命令要求 PostgreSQL 遍歷表格並更新其用於查詢計劃估算的內部統計資訊(查詢計劃分析將在稍後討論)。
ANALYZE nyc_census_blocks;
15.5. 清理¶
值得強調的是,僅建立索引不足以讓 PostgreSQL 有效地使用它。每當針對表格發出大量 UPDATE、INSERT 或 DELETE 時,都必須執行 VACUUM。VACUUM 命令要求 PostgreSQL 回收表格頁面中因更新或刪除記錄而留下的任何未使用空間。
清理對於資料庫的有效運作至關重要,因此 PostgreSQL 預設提供「自動清理」功能。
自動清理會在由活動程度決定的合理間隔中清理(回收空間)和分析(更新統計資訊)您的表格。雖然這對於高度交易型的資料庫至關重要,但不建議在加入索引或大量載入資料後等待自動清理執行。每當執行大量批次更新時,您應該手動執行 VACUUM。
可以根據需要分別執行清理和分析資料庫。發出 VACUUM 命令不會更新資料庫統計資訊;同樣,發出 ANALYZE 命令也不會回收未使用的表格列。這兩個命令都可以針對整個資料庫、單個表格或單個列執行。
VACUUM ANALYZE nyc_census_blocks;
15.6. 函數列表¶
geometry_a && geometry_b:如果 A 的邊界框與 B 的重疊,則返回 TRUE。
geometry_a = geometry_b:在 PostGIS 2.4 之前,如果 A 的邊界框與 B 的相同,則返回 true。從 2.4 開始,只有當 A 的幾何圖形與 B 的相同時,才返回 TRUE。
geometry_a ~= geometry_b:如果 A 的邊界框等於 B 的邊界框,則返回 TRUE。
ST_Intersects(geometry_a, geometry_b):如果幾何/地理空間「空間相交」(共享任何空間部分),則返回 TRUE,如果它們不相交(它們是分離的),則返回 FALSE。
腳註
