27. 索引叢集¶
資料庫擷取資訊的速度取決於從磁碟讀取資料的速度。小型資料庫會完全載入 RAM 快取,並擺脫實體磁碟的限制,但對於大型資料庫來說,存取實體磁碟將成為磁碟存取速度的瓶頸。
資料是以機會性的方式寫入磁碟,因此磁碟上資料的儲存順序與應用程式存取或組織資料的方式之間不一定有任何關聯。
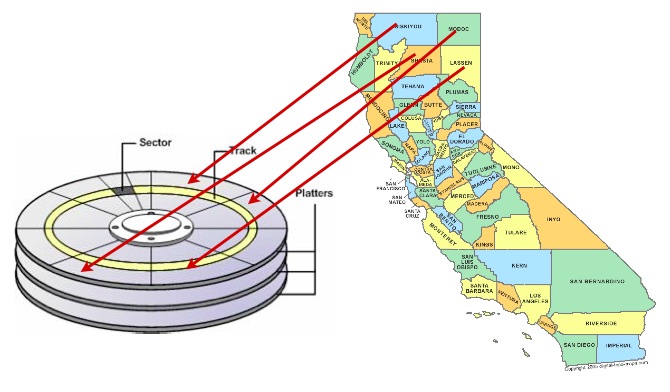
加快資料存取速度的一種方法是確保可能在同一個結果集中一起擷取的記錄位於硬碟盤片上類似的實體位置。這稱為「叢集」。
要使用的正確叢集方案可能很棘手,但一般規則適用:索引定義了資料的自然排序方案,該方案與擷取資料時將使用的存取模式類似。
因此,以與索引相同的順序將資料排序到磁碟上,在某些情況下可以提供速度優勢。
27.1. R 樹上的叢集¶
空間資料傾向於在空間相關的視窗中存取:想想網頁或桌面應用程式中的地圖視窗。視窗中的所有資料都具有相似的位置值(否則就不會在視窗中!)。
因此,基於空間索引的叢集對於將使用空間查詢存取的空間資料而言是有意義的:相似的事物傾向於具有相似的位置。
讓我們根據空間索引叢集我們的 nyc_census_blocks。
-- Cluster the blocks based on their spatial index
CLUSTER nyc_census_blocks USING nyc_census_blocks_geom_idx;
該命令會按照空間索引 nyc_census_blocks_geom_gist 定義的順序重新寫入 nyc_census_blocks。您能感受到速度差異嗎?也許沒有,因為原始資料可能已經有一些預先存在的空間順序(這在 GIS 資料集中並不少見)。
27.2. 磁碟與記憶體/SSD¶
大多數現代資料庫都使用 SSD 儲存,其隨機存取速度比舊的旋轉磁性媒體快得多。此外,大多數現代資料庫都運行在足夠小以放入資料庫伺服器 RAM 中的資料之上,並作為作業系統「虛擬檔案系統」快取最終放在那裡。
叢集仍然必要嗎?
令人驚訝的是,是的。在空間中「彼此靠近」的記錄在記憶體中「彼此靠近」可以提高相關記錄一起移動到伺服器「記憶體快取階層」的機率,從而加快記憶體存取速度。
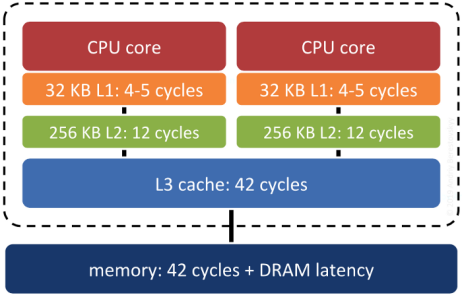
系統 RAM 不是現代電腦上最快的記憶體。系統 RAM 和實際 CPU 之間有幾個層級的快取,底層的作業系統和處理器會以區塊的形式在快取階層中上下移動資料。如果被移動的區塊正好包含系統下一步需要的資料……那將會是一個很大的勝利。將記憶體結構與空間結構關聯起來是一種增加這種勝利發生的機率的方法。
27.3. 索引結構重要嗎?¶
理論上來說,是的。實際上,並不是真的。只要索引是資料的「相當好」的空間分解,效能的主要決定因素將是實際資料表元組的順序。
「沒有索引」和「有索引」之間的差異通常很大且高度可測量。「平庸的索引」和「優良的索引」之間的差異通常需要非常仔細的測量才能辨別,並且可能對正在測試的工作負載非常敏感。
