40. 進階幾何建構¶
nyc_subway_stations 圖層到目前為止為我們提供了許多有趣的範例,但它有一些顯著之處
雖然它是一個包含所有車站的資料庫,但它不容易視覺化路線!在本章中,我們將使用 PostgreSQL 和 PostGIS 的進階功能,從地鐵站的點圖層建構一個新的線性路線圖層。
我們的任務特別困難,有兩個問題
nyc_subway_stations的routes欄位在每一列中都有多個路線識別符,因此可能出現在多條路線中的車站在表格中只會出現一次。與前一個問題相關,車站表格中沒有路線排序資訊,因此雖然可以找到特定路線中的所有車站,但無法使用屬性來確定列車經過車站的順序。
第二個問題比較困難:給定路線中一組無序的點,我們如何對它們進行排序以符合實際路線。
以下是「Q」線的停靠站
SELECT s.gid, s.geom
FROM nyc_subway_stations s
WHERE (strpos(s.routes, 'Q') <> 0);
在這張圖片中,停靠站以其唯一的 gid 主鍵標記。
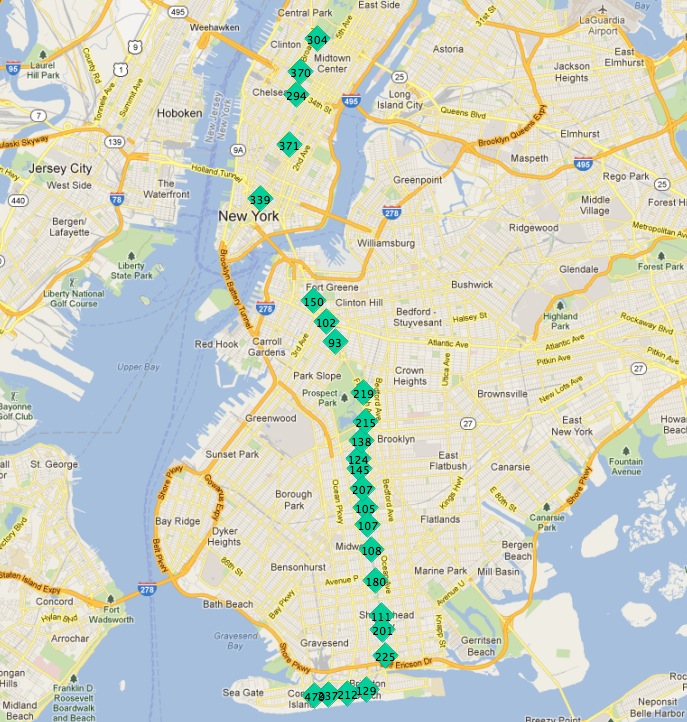
如果我們從其中一個終點站開始,該線上接下來的車站似乎總是最近的。我們可以每次重複這個過程,只要我們從搜尋中排除所有先前找到的車站。
在資料庫中執行這種迭代例程有兩種方法
通用表格表達式 (CTE) 的優點是不需要執行函數定義。以下是計算「Q」線路線的 CTE,從最北端的停靠站開始(其中 gid 為 304)。
WITH RECURSIVE next_stop(geom, idlist) AS (
(SELECT
geom,
ARRAY[gid] AS idlist
FROM nyc_subway_stations
WHERE gid = 304)
UNION ALL
(SELECT
s.geom,
array_append(n.idlist, s.gid) AS idlist
FROM nyc_subway_stations s, next_stop n
WHERE strpos(s.routes, 'Q') != 0
AND NOT n.idlist @> ARRAY[s.gid]
ORDER BY ST_Distance(n.geom, s.geom) ASC
LIMIT 1)
)
SELECT geom, idlist FROM next_stop;
CTE 由兩個部分組成,它們聯合在一起
第一部分為表達式建立一個起點。我們取得初始幾何圖形並初始化已訪問的識別符陣列,使用「gid」為 304(線路末端)的記錄。
第二部分迭代直到找不到其他記錄。在每次迭代中,它通過對「next_stop」的自我引用取得先前迭代的值。我們搜尋 Q 線上的每個停靠站 (strpos(s.routes,’Q’)),這些停靠站我們尚未添加到我們的已訪問列表 (NOT n.idlist @> ARRAY[s.gid]) 中,並根據它們與先前點的距離對它們進行排序,只取第一個(最近的)。
除了遞迴 CTE 本身之外,這裡還使用了許多進階 PostgreSQL 陣列功能
我們正在使用 ARRAY! PostgreSQL 支援任何類型的陣列。在這種情況下,我們有一個整數陣列,但我們也可以建構幾何圖形陣列或任何其他 PostgreSQL 類型。
我們正在使用 array_append 來建構我們的已訪問識別符陣列。
我們正在使用 @> 陣列運算子(「陣列包含」)來尋找我們已訪問過的 Q 線車站。 @> 運算子在兩側都需要 ARRAY 值,因此我們必須使用 ARRAY[] 語法將單個「gid」數字轉換為單條目的陣列。
當您執行查詢時,您會依找到的順序(也就是路線順序)取得每個幾何圖形,以及已訪問過的識別符列表。將幾何圖形包裝到 PostGIS ST_MakeLine 聚合函數中,會將幾何圖形集轉換為單一的線性輸出,並依提供的順序建構。
WITH RECURSIVE next_stop(geom, idlist) AS (
(SELECT
geom,
ARRAY[gid] AS idlist
FROM nyc_subway_stations
WHERE gid = 304)
UNION ALL
(SELECT
s.geom,
array_append(n.idlist, s.gid) AS idlist
FROM nyc_subway_stations s, next_stop n
WHERE strpos(s.routes, 'Q') != 0
AND NOT n.idlist @> ARRAY[s.gid]
ORDER BY ST_Distance(n.geom, s.geom) ASC
LIMIT 1)
)
SELECT ST_MakeLine(geom) AS geom FROM next_stop;
看起來像這樣
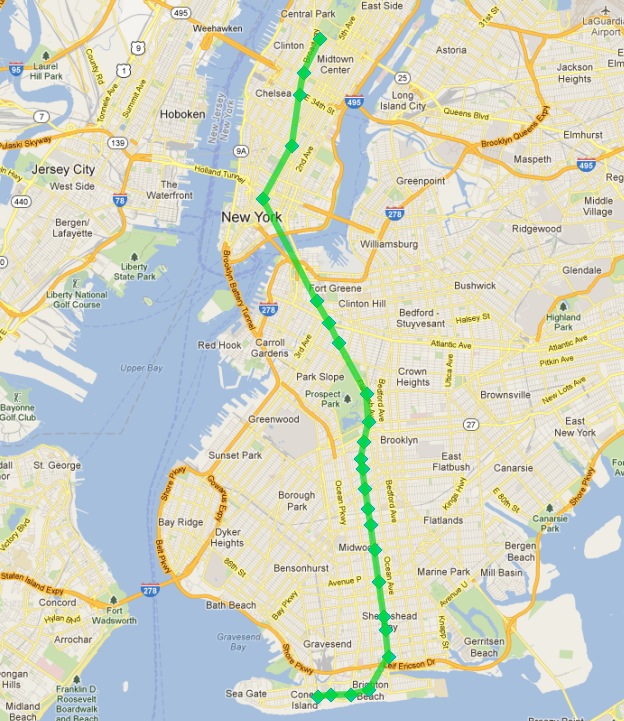
成功!
但是,有兩個問題
我們這裡只計算了一條地鐵路線,我們想要計算所有路線。
我們的查詢包含一個先驗知識,即作為建構路線的搜尋演算法種子的初始車站識別符。
讓我們首先解決難題,在不手動檢查構成路線的車站集的情況下,找出路線上的第一個車站。
我們的「Q」線停靠站可以作為起點。路線的終點站有什麼特點?
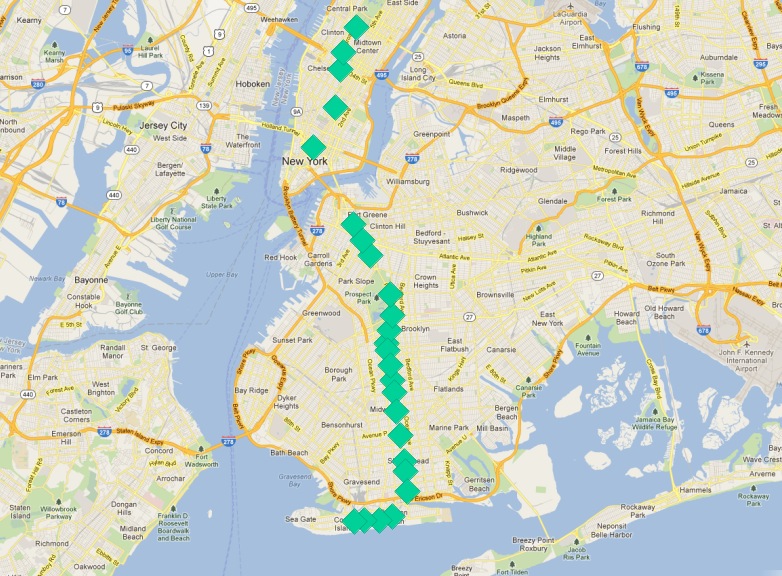
一個答案是「它們是最北端和最南端的車站」。但是,想像一下,如果「Q」線從東向西運行。條件仍然成立嗎?
終點站的一個較少方向性的特徵是「它們是距離路線中間最遠的車站」。有了這個特徵,路線是南北向還是東西向運行都沒關係,只要它或多或少沿一個方向運行,尤其是在兩端。
由於沒有 100% 的啟發式方法來找出終點,讓我們嘗試一下第二個規則。
注意
「距離中間最遠」規則的一個明顯失敗模式是環狀線,例如英國倫敦的環線。幸運的是,紐約沒有這樣的路線!
要找出每條路線的終點站,我們首先必須找出有哪些路線!我們找出不同的路線。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
)
SELECT * FROM routes;
請注意兩個進階 PostgreSQL ARRAY 函數的使用
string_to_array 接收一個字串,並使用分隔符將其拆分為陣列。PostgreSQL 支援任何類型的陣列,因此可以建構字串陣列,如本例所示,也可以建構幾何圖形和地理陣列,我們將在本例中稍後看到。
unnest 接收一個陣列,並為陣列中的每個條目建構一個新列。效果是將嵌入在單一列中的「水平」陣列轉換為「垂直」陣列,每個值都有一列。
結果是所有唯一地鐵路線識別符的清單。
route
-------
1
2
3
4
5
6
7
A
B
C
D
E
F
G
J
L
M
N
Q
R
S
V
W
Z
(24 rows)
我們可以藉由將此結果連結回 nyc_subway_stations 表格來建構此結果,以建立一個新表格,該表格針對每條路線,為該路線上的每個車站都有一個列。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
)
SELECT * FROM stops;
gid | geom | route
-----+----------------------------------------------------+-------
2 | 010100002026690000CBE327F938CD21415EDBE1572D315141 | 1
3 | 010100002026690000C676635D10CD2141A0ECDB6975305141 | 1
20 | 010100002026690000AE59A3F82C132241D835BA14D1435141 | 1
22 | 0101000020266900003495A303D615224116DA56527D445141 | 1
...etc...
現在我們可以透過將每條路線的所有車站收集到一個多點中,並計算該多點的質心來找到中心點。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
),
centers AS (
SELECT ST_Centroid(ST_Collect(geom)) AS geom, route
FROM stops
GROUP BY route
)
SELECT * FROM centers;
「Q」線停靠站的中心點看起來像這樣
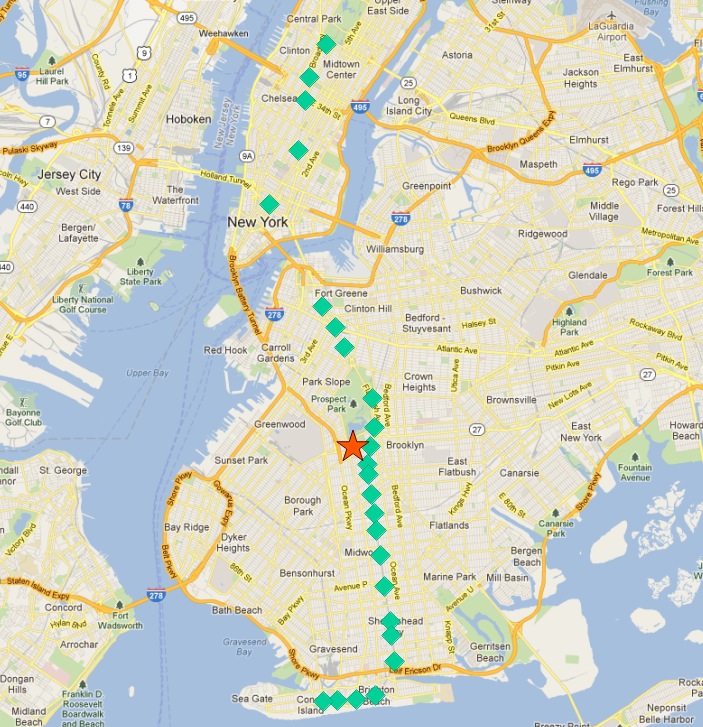
因此,最北端的停靠站(終點)似乎也是距離中心最遠的停靠站。讓我們計算每條路線的最遠點。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
),
centers AS (
SELECT ST_Centroid(ST_Collect(geom)) AS geom, route
FROM stops
GROUP BY route
),
stops_distance AS (
SELECT s.*, ST_Distance(s.geom, c.geom) AS distance
FROM stops s JOIN centers c
ON (s.route = c.route)
ORDER BY route, distance DESC
),
first_stops AS (
SELECT DISTINCT ON (route) stops_distance.*
FROM stops_distance
)
SELECT * FROM first_stops;
這次我們新增了兩個子查詢
stops_distance 將中心點連結回車站表格,並計算每條路線的車站與中心之間的距離。結果會排序,使得記錄針對每條路線以批次形式輸出,最遠的車站是批次的第一個記錄。
first_stops 藉由僅取每個不同群組的第一個記錄來篩選 stops_distance 的輸出。由於我們對 stops_distance 進行排序的方式,第一個記錄是最遠的記錄,這意味著它是我們想要用作起點種子來建構每條地鐵路線的車站。
現在我們知道每條路線,而且我們(大致)知道每條路線從哪個車站開始:我們準備好產生路線了!
但是首先,我們需要將我們的遞迴 CTE 表達式轉換為一個可以使用參數呼叫的函數。
CREATE OR REPLACE function walk_subway(integer, text) returns geometry AS
$$
WITH RECURSIVE next_stop(geom, idlist) AS (
(SELECT
geom AS geom,
ARRAY[gid] AS idlist
FROM nyc_subway_stations
WHERE gid = $1)
UNION ALL
(SELECT
s.geom AS geom,
array_append(n.idlist, s.gid) AS idlist
FROM nyc_subway_stations s, next_stop n
WHERE strpos(s.routes, $2) != 0
AND NOT n.idlist @> ARRAY[s.gid]
ORDER BY ST_Distance(n.geom, s.geom) ASC
LIMIT 1)
)
SELECT ST_MakeLine(geom) AS geom
FROM next_stop;
$$
language 'sql';
現在我們準備好了!
CREATE TABLE nyc_subway_lines AS
-- Distinct route identifiers!
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
-- Joined back to stops! Every route has all its stops!
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
),
-- Collects stops by routes and calculate centroid!
centers AS (
SELECT ST_Centroid(ST_Collect(geom)) AS geom, route
FROM stops
GROUP BY route
),
-- Calculate stop/center distance for each stop in each route.
stops_distance AS (
SELECT s.*, ST_Distance(s.geom, c.geom) AS distance
FROM stops s JOIN centers c
ON (s.route = c.route)
ORDER BY route, distance DESC
),
-- Filter out just the furthest stop/center pairs.
first_stops AS (
SELECT DISTINCT ON (route) stops_distance.*
FROM stops_distance
)
-- Pass the route/stop information into the linear route generation function!
SELECT
ascii(route) AS gid, -- QGIS likes numeric primary keys
route,
walk_subway(gid, route) AS geom
FROM first_stops;
-- Do some housekeeping too
ALTER TABLE nyc_subway_lines ADD PRIMARY KEY (gid);
以下是我們在 QGIS 中視覺化的最終表格
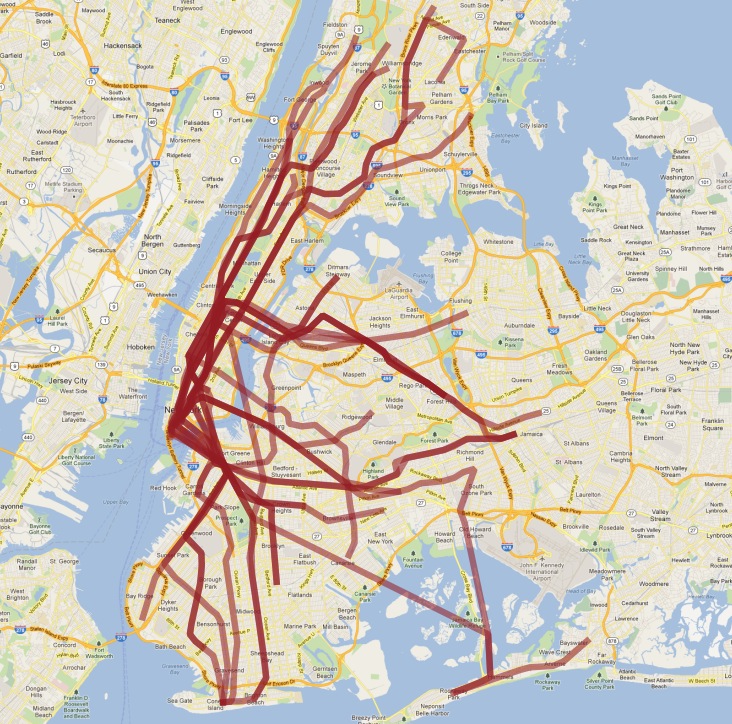
像往常一樣,我們對資料的簡單理解存在一些問題
實際上,有兩條「S」(短距離「接駁」)列車,一條在曼哈頓,另一條在洛克威,我們將它們連接在一起,因為它們都稱為「S」;
「4」線(以及其他一些線路)在一條線路的末端分裂成兩個終點站,因此「遵循一條線路」的假設被打破,結果在末端有一個有趣的鉤子。
希望這個範例讓您體驗到結合 PostgreSQL 和 PostGIS 的進階功能可以進行的一些複雜資料操作。
